Abstract
Image vectorization is a powerful technique that converts raster images into vector graphics, enabling enhanced flexibility and interactivity. However, popular image vectorization tools struggle with occluded regions, producing incomplete or fragmented shapes that hinder editability. While recent advancements have explored rule-based and data-driven layer-wise image vectorization, these methods face limitations in vectorization quality and flexibility.
In this paper, we introduce LayerPeeler, a novel layer-wise image vectorization approach that addresses these challenges through a progressive simplification paradigm. The key to LayerPeeler's success lies in its autoregressive peeling strategy: by identifying and removing the topmost non-occluded layers while recovering underlying content, we generate vector graphics with complete paths and coherent layer structures. Our method leverages vision-language models to construct a layer graph that captures occlusion relationships among elements, enabling precise detection and description for non-occluded layers. These descriptive captions are used as editing instructions for a finetuned image diffusion model to remove the identified layers. To ensure accurate removal, we employ localized attention control that precisely guides the model to target regions while faithfully preserving the surrounding content. To support this, we contribute a large-scale dataset specifically designed for layer peeling tasks. Extensive quantitative and qualitative experiments demonstrate that LayerPeeler significantly outperforms existing techniques, producing vectorization results with superior path semantics, geometric regularity, and visual fidelity.
How does it work?

Given a rasterized source image (parrot), our system leverages vision-language models to analyze the image across three dimensions:
(1) constructing a layer graph that captures occlusion relationships among color regions,
(2) identifying the topmost layers and generating a global prompt that describes them,
(3) decomposing the topmost layers into instance-level elements, each with an associated prompt and bounding box.
The prompts and source image are encoded through text and image encoders to obtain $c_e$ and $x_\mathrm{src}$, respectively, while a noise vector $z_T$ is initialized. These inputs are fed into our LoRA-finetuned diffusion model, which synthesizes an image with the specified layers removed.
The bounding boxes guide attention masks within joint attention modules.
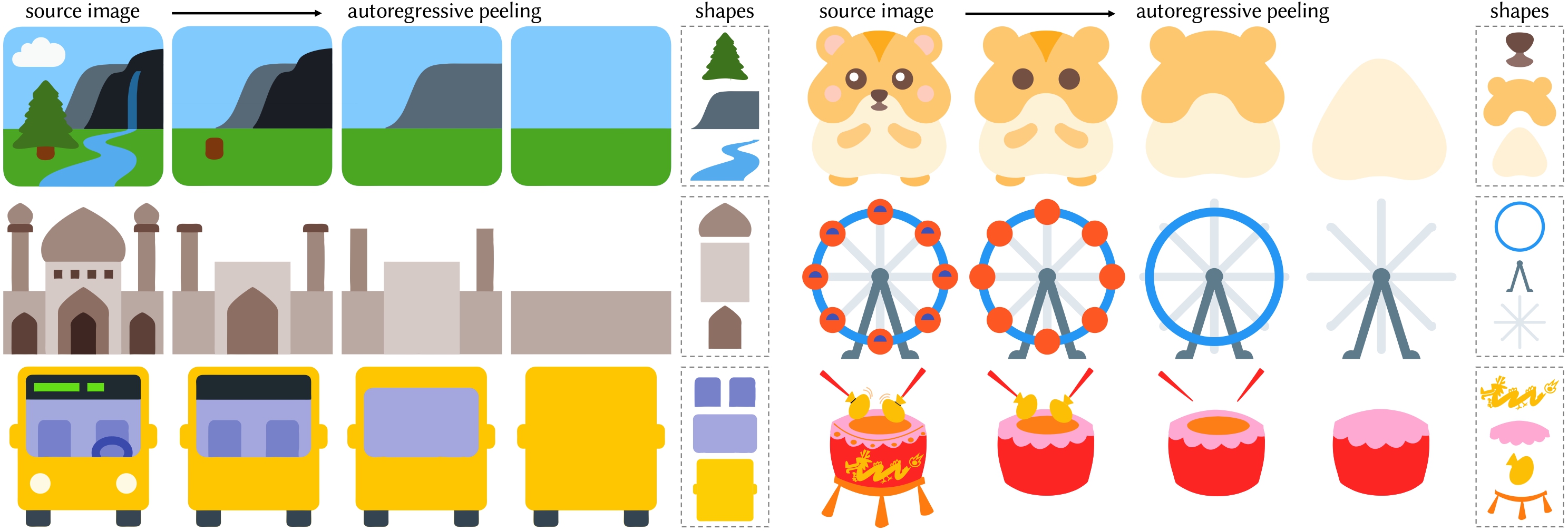
This layer removal process operates autoregressively, iteratively identifying and removing topmost layers until a complete layer-wise decomposition is achieved.
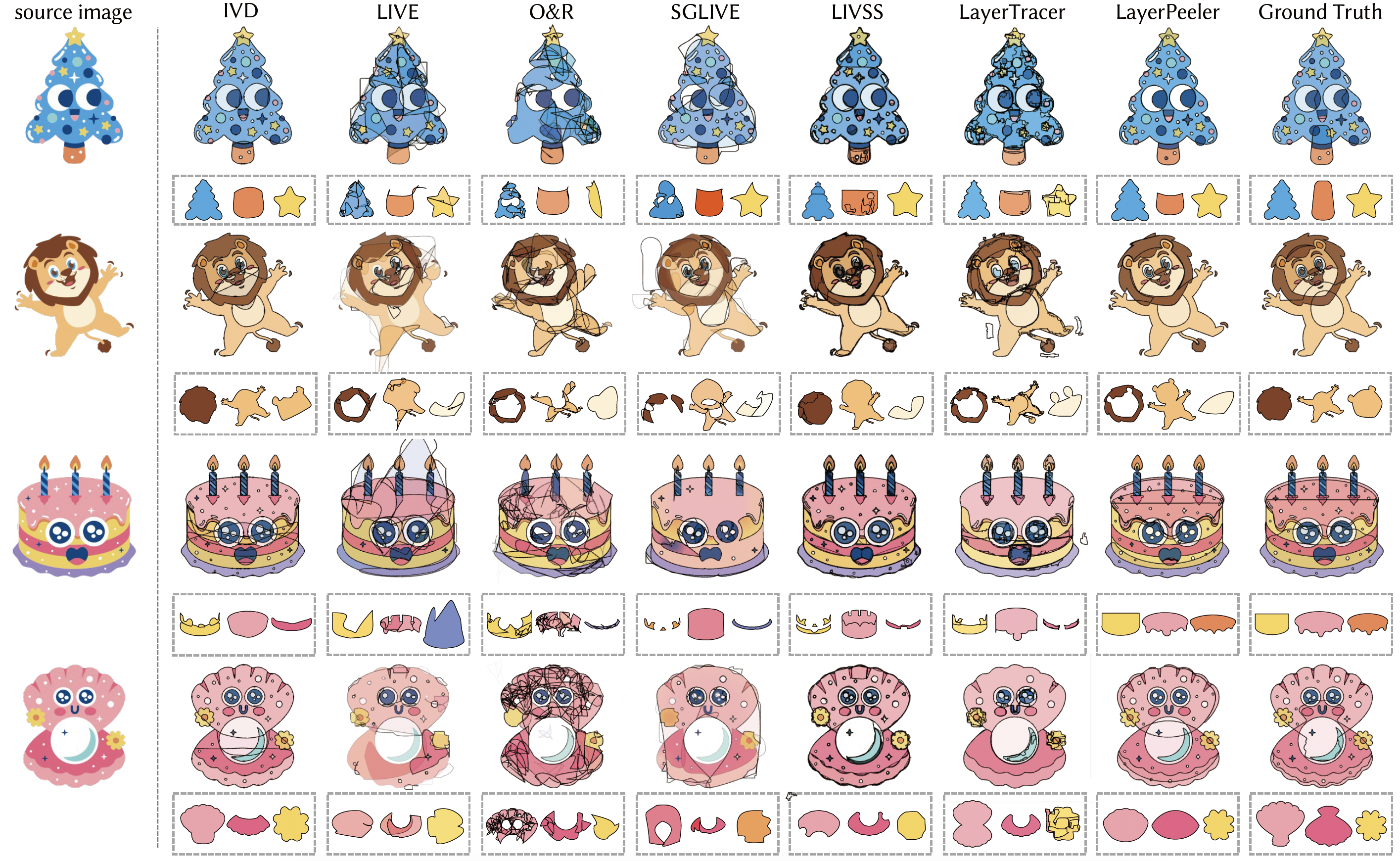
Gallery
These gifs show that each path is regular and complete.











































































































































































































































































































































































































































































































Varying the Style

Complex Images